The psycho-biological quest
Goded Shahaf MD PhD
* This manuscript is under the constant process of expansion and re-writing
** Please feel free to write suggestions/comments/requests to psycho.biological.quest@gmail.com
Contents
1. The big wishes: happiness and wisdom
1.1. Happiness is our ultimate goal
1.2. Wisdom is the major tool for increasing happiness
2. Transforming psychological questions to biological ones
2.1. Motivation
2.2. Transform fundamentals
2.2.1 The principle of representation
2.2.2. The principle of activity-dependent change
2.2.3. The principle of drives regulation
3. The transform of happiness and its implications
3.1. Happiness as effective drive regulation
3.2. Psycho-biological pitfalls perpetuate unhappiness
3.3. Overcoming the perpetuating psycho-biological pitfalls – TBD
4. The transform of wisdom (theory building) and its implications
4.1. The principles of theorizing and its comprehensive generalization
4.2. Analysis of scientific advancement – TBD
4.3. Comprehensive expansion of our ability to form theories – TBD
1. The big wishes: happiness and wisdom
1.1. Happiness is our ultimate goal
We all want to be happy. Or should we say, all we really want is to be happy? However, the concept of happiness seems to evade conclusive definition, which would be generally agreeable. Definitely, in lay-terms, different people have different definitions for happiness. Furthermore, even if we reach some personal definition for happiness, it might involve different time-scales. Thus, we may be happy due to some activity we are doing today, but generally un-happy due to a certain state, which will last throughout the year, etc. Hopefully, it would be possible to arrive at an effective definition of happiness with the progress of this manuscript. But, for now, let us just mark happiness as the ultimate goal of our quest.
1.2. Wisdom is the major tool for increasing happiness
Even before we define what happiness is, it seems that it may depend on our ability to overcome difficulties, in one way or the other. Indeed, the specifics of the way (and possibly also the characterization of the nature of difficulties) is likely to be dependent on the specific definition we choose for happiness. However, it seems that, in general, happiness depends on our abilities to overcome difficulties (even, if the definition of difficulties and their overcoming might be variable). Wisdom can help us overcoming difficulties and it can enrich our abilities to do so. For example, some of these difficulties and abilities might relate to our physical environment and others to our social environment. But, all in all, it seems that wisdom has the potential to be a major tool for overcoming difficulties and for obtaining happiness.
Therefore, let me try and provide the outlines of a general operational (practical and measurable) definition for wisdom. According to this definition, wisdom would be the ability to build effective theories about our environment – whether physical, social, or any other specification of environment we may choose. In the context of harnessing wisdom, for overcoming difficulties and for increasing happiness, the term “effective theory” means that theories should be evaluated by their usefulness for us – in terms of prediction of dynamics and change in our environments and in terms of enabling us to interfere and impact such dynamics, for our benefit.
Indeed, we always aim at improving our working tools, so as to enable the building of more effective theories about our environment. Thus, physicists might strive for better telescopes, better particle accelerators, etc.; biologists might be after improved microscopes, improved DNA chips, etc.; also, psychologists are interested in improving the means of evaluating various types of behavior, by using better questionnaires and by improving methods of collecting behavioral data from more naturalistic settings, which might be different from the “sterile” conditions at the laboratory or clinics. Furthermore, in our era, we witness the accumulation of large datasets of information in these (and other) areas of research and inquiry. Thence, we also see deep interest, in all research fields, in the enhanced development of tools for data mining, which aim at extracting rules of association between the bits of information in these growing datasets.
In a way, such enhanced data mining is an expansion of the human ability to build effective theories. But, the selection, or the development, of the specific data mining method for a specific dataset, and the interpretation of results, is under human supervision. Still, we could ask ourselves, what if it would be possible to expand our abilities for building theories (or, in other words, to expand our wisdom) in a more systematic and comprehensive manner. Indeed, if impactful, such an expansion might be a breakthrough in our ability to build effective theories about our environment in each and every field of interest and of human activity.
Thus, altogether, this manuscript aims at modeling two grand outcomes of the human mind – happiness and wisdom (theory building). Indeed, theory building is modeled under the scope of its effective harnessing for overcoming difficulties and for enhancing relevant abilities in the route to happiness.
2. Transforming psychological questions to biological ones
2.1. Motivation
However, how can one aspire to model such complex processes of the human mind as happiness and theory building? Indeed, psychology, which is the field of research and inquiry of the human mind, offers various models and theories for both happiness and theory building. However, it does not seem to offer a conclusive and comprehensive theory, but rather a set of partial theories, which often offer conflicting models and, furthermore, seem to be based on some preliminary, rather arbitrary assumptions.
On the other hand, the mind is embedded in the brain, which is a biological substrate. In psycho-biology we assume that it should be possible to map every psychological (or behavioral) process, complex as it may be, to its biological counterpart. Certainly, we constantly learn new facts in the field of neurobiology (biology of the brain). But, we seem to have acquired sufficient knowledge to be able to map, to a sufficient degree, between psychological processes and their biological embodiments, even when we discuss such complex processes, which underlie wisdom (theory building), or happiness (once we define it operationally as well). In-fact, it may be that this acquired neurobiological knowledge may impose significant constraints upon these allegedly complex behavioral processes and could serve as a basis for their effective modeling.
2.2. Transform fundamentals
A transform is a term, which is used to describe the mapping of representations between two different domains. In-fact, a transform is useful if it can map a problem, which appears complex in one domain, into a problem, which might be solvable in another domain. For example, Fourier transform is used to map between the representation of a signal as changes of amplitude over time, on the one hand, and the representation of the signal as a summation of activity in underlying frequency bands. Thus, Fourier transform can serve, for example, to focus upon (filter) certain frequency bands of interest in the signal. Indeed, this prevalent use of Fourier transform to filter signals is but one example of its utilization. Furthermore, there are multiple other transforms with multiple other utilizations.
Often, a transform is based upon fundamental sets of representations. Where, in each domain the more complex representations could be described as a combination of the corresponding fundamental set, and whereby there is a mapping between the constituents in one fundamental set and the constituents of the other fundamental set.
Thus, we will borrow the term (without adhering to its strict mathematical formalism) and will define the psycho-biological transform as an effective mapping between psychological processes and their underlying neurobiological processes. Similar to the more formal transforms, we will discuss below three fundamental principles, which may underlie, the neurobiological embodiments of complex psychological, or behavioral, processes.
2.2.1 The principle of representation
Eventually, any behavior, complex or simple, manifests through actions performed by the individual, often, in response to sensed stimuli. Thus, it may be possible to consider the brain as a tool, which generates certain responses following exposure to certain stimuli. Obviously, the responses could be significantly delayed, e.g. when they are related to learned and memorized stimuli, which occurred in the past. But, the general notion of the brain as a tool, which relates stimuli and responses, seems valid.
Interestingly, for every specific response, we can identify a set of (motor) neurons, which when active in specific patterns, evoke the response. Similarly, for every specific sensation of stimulus, we can identify a set of (sensory) neurons, in which specific patterns of activity are evoked due to the specific stimulus sensation. Thus, basically, there are specific neuronal networks, with specific patterns of activity, which underlie stimuli sensation and there are specific neuronal networks, with specific patterns of activity, which underlie motor responses. Furthermore, we know these networks are localized, in the nervous system, in limited sensory modules and in limited motor modules, respectively. We also know that more complex sensations involve “higher” sensory and perceptual modules, which combine representations from multiple “lower” sensory modules (that represent sensations of sub-components of the complex sensation). For example, perception of faces, at a higher perceptual module, is based on the sensation of sets of relevant lines, angles, colors, etc., each embedded in specific lower sensory modules. Similarly, more complex responses involve higher motor, or executive, modules, which activate in a relevant pattern, lower motor modules (that represent sub-actions in the complex response). For example, speaking, which is represented at a higher motor module, evokes the relevant activity in “lower” motor modules, which represent movements of specific articulation muscles.
However, we know there is a limited number of representational brain modules. Furthermore, we know that, within each module, there is a limit on the number of possible alternative representations (e.g. possible alternative faces) and also limitations on their simultaneous activation. Certainly, some of the details with regard to the representational role of different brain modules are still learned. Moreover, the limitations upon the capacity for multiple representations within a module and upon simultaneous activations of representations in a module, are even less well defined at the current stage. In-fact, it is certain that the brief description of representation, presented above, is very coarse and could be elaborated. However, all in all, representation is based upon a limited set of modules, each with an expertise in a specific type of stimuli or specific type of responses. As was suggested, some of these representations are more basic and some combine basic representations hierarchically to form more complex representations. Yet, due to the limitation on the number of modules and on the capacity of alternative representations in each module, the brain’s representation span is rather limited.
2.2.2. The principle of activity-dependent change
Beyond the representation of specific stimuli and of specific responses, the brain, as an input-output (stimuli-responses) tool, is based upon associations. Thus, there are associations between representations of stimuli and representations of responses and also associations among the representations of stimuli themselves and among the representations of responses themselves. In-fact, we already discussed how stimulus representations by themselves and response representations by themselves could form associations in a hierarchical manner, from simpler to more complex. Having emphasized the hierarchical association, it is important to state that, to a certain degree, representations can also associate non-hierarchically. Furthermore, importantly, the association might involve more than just pairs of representations. For example, the combination of multiple representations of sensed stimuli might evoke the activation of a specific response. Indeed, the association of multiple representations is also prevalent within the stimulus representations themselves and within the response representations themselves.
However, we have the ability to learn and change our perception of stimuli, our responses, and the manner we respond to specific sensed stimuli. Therefore, the associations between the brain’s representations are changeable. In-fact, the change of association depends on the patterns of co-activation and separate activation of the involved representations. Thus, representations, which tend to be active in synchrony, tend to associate and, vice a versa, representations, which tend to be active separately from one another, tend to dissociate (the principle of “fire together, wire together”). Certainly, we still learn the fine intricacies of this principle. However, the general principle is that we learn and update our perceptions repertoire, our responses repertoire and our associations between perceptions and responses on this well-established basis of activity-dependent change. Notably, this principle can shape not only representation associations, but also the representations themselves. As, basically, complex representations are combinations of more basic representations, the degree of co-occurrence between these basic representations will compose or decompose the complex representations.
2.2.3. The principle of drives regulation
However, some stimuli, which may convey greater importance to the individual, evoke greater activity in the brain, or are more driving, than other stimuli. In-fact, it seems possible to grade the stimuli based on their driving of relevant brain activity. Thus, the more driving stimuli (or drives) have a higher likelihood to evoke responses and are more likely to induce activity-dependent change and learning. To begin with, some stimuli seem to be pre-wired as drives to evoke greater brain activity due to evolutionary concerns – e.g. stimuli, which relate to basic needs, such as hunger and thirst. However, due to the principle of co-activation-based learning (“fire together, wire together”), other stimuli might also acquire strong driving properties due to their co-occurrence with the pre-wired drives, or with other stimuli, which already acquired such driving properties. Similarly, some stimuli might lose driving properties, when their synchronization with other drives reduces.
Yet, if a stimulus acts upon our sensation only briefly, it is less likely to have a driving effect and to evoke responses and learning (activity dependent change). Therefore, driving stimuli are generally active for long periods, either because the stimulus continues to be sensed by the brain (e.g. hunger), or because the brain reverberates it by internal activation of its representation (e.g. the memory of a significant event). Thus, long acting drives may continue to generate responses and may continue to change the associations of internal representation for a long period. However, in this process, responses might be evoked (or, in other terms, they might be associated with the stimulus by way of activity-dependent change, and thereby they might be evoked). Possibly, many responses might not affect the driving stimuli, and the representation of the driving stimuli will continue to be active. But, some responses might abort the driving stimulus – e.g. eating aborts hunger and more complex responses might abort more complex driving stimuli – as if the drive was satisfied. At this point, the activation of the stimulus representation halts. However, this means that the association, which may have recently formed, between the representation of the driving stimulus and the representation of the relevant (drive reducing) response would stabilize – as the neural activity, which is necessary to change it, reduces and activity-dependent change stops. In-fact, the next time this drive representation is evoked, the drive reducing response would be evoked earlier (because the drive-response association was already established) and thereby the association between the drive and the drive-reducing response will stabilize. Certainly, we still learn the intricacies of this stabilization (e.g. by searching for neural embodiments of reward). But, there seems to be a solid basis for the general principle of drives regulation, which is comprised of: (1) stimuli gaining (or losing) driving properties, based on level of synchronization with other drives (starting with pre-wired drives); (2) drive-induced lasting activation of the brain, which leads to activity-dependent change and “exploration”, which may generate various responses; and (3) association between driving stimuli and drive reducing responses.
In the next chapters we will utilize these 3 fundamental principles (representation, activity-dependent change and drives regulation) for transforming the allegedly complex psychological phenomena of happiness and wisdom (or theory building) to well-defined neurobiological processes, which may provide practical insight for the enhancement of both wisdom and happiness.
3. The transform of happiness and its implications
3.1. Happiness as effective drive regulation
Let us discuss the psycho-biological transform of happiness and start by looking at the biological aspects of happiness. Indeed, there is strong association between emotions and specific physiological manifestations, such as increased heart rate, sweating, certain facial expressions, etc. In-fact, this association is so well established that the perception of our own emotions has been suggested to be based on sensation of these bodily responses. Thus, according to this line of thought (see James-Lange theory of emotions), similar to the way we perceive concrete objects, on the basis of sensing external stimuli, we also perceive emotions, on the basis of sensing internal stimuli (these responses of our body).
Nevertheless, this line of thought poses challenges. Indeed, one of the fundamental challenges is that it seems there is a large overlap in the physiological responses, which are associated with both negative and positive emotions. For example, both fear and joy may involve increased heart rate, etc. Still, research in this field seems to identify differences in the temporal patterns of these partially overlapping physiological responses. Thus, it may be that, for negative emotions, physiological recruitment is rather high over longer periods of time, while for positive emotions there is, apparently, greater temporal dynamics. In-fact, it often seems possible to find, during the processing of positive emotions, periodic switches between higher level of physiological recruitment and lower level of recruitment. Interestingly, these alternating periods, during the processing of positive emotions may last several tens of seconds at a time, even though their timing is not punctual.
Notably, when negative emotions are concerned, the higher level of relevant physiological responses seems to be associated with increased stress. Therefore, it might be possible to envision the processing of positive emotions, as comprised from a series of stressing perceptions of stimuli (or a set of drives). Possibly, the increased physiological response, evoked by each of the drives in the series, subsides after the generation of a relevant response, which was previously associated with the drive (whether external – acting upon the environment, or internal – within the brain). Indeed, elementary responses to stimuli by our brain, would usually occur in the sub-second timescale. Therefore, if the processing of emotional stimuli lasts tens of seconds, it probably involves the evoking of perceptions of multiple driving stimuli, each of which may be followed by a relevant response. In-fact, the evoking of such a series of drives and responses might be expected during the processing of information, which bears emotional significance and therefore is likely to involve rich associations, which may evoke (perception of) multiple significant stimuli (drives).
However, this possible explanation for the difference in the dynamics of the physiological responses, between positive emotions and negative emotions, seems to accord with the drive regulation principle, which was presented above. Thus, during the processing of drives, which evoke negative emotions, the stressing drive/drives is/are unresolved, as is manifested by the continuous high level of relevant physiological responses. On the other hand, during the processing of a set of drives, which evokes positive emotions, the brain generates a series of effective responses that can regulate the various drives involved. Thereby, each such drive regulation reduces stress temporarily (until the onset of another drive in the series) and manifests as a period of relaxation in the physiological response. Altogether, this may suggest that positive emotions, at-least as far as they are related to our physiological responses, may be the product effective drive regulation. On the other hand, negative emotions may be related with the lack of ability to regulate drives effectively. Thus, if we consider happiness as the hallmark of positive emotions, it is possible to conclude that happiness is based on the ability to regulate our drives effectively.
Yet, what does it mean to regulate drives effectively? Indeed, it seems that certain solutions to drives, which might reduce them in the short run, would evoke, in the longer run, even more challenging drives. For example, we may crave for certain types of food (and, therefore, these foods are drives), which might lead, in the longer run, to various medical complications, likely to manifest as more stressing (and difficult to resolve) drives. Indeed, this is where effective theory building (or wisdom) comes into play. Thus, more effective theories would improve our ability to predict longer-run formation of drives. Furthermore, more effective theories may also provide us with better responses to regulate the combination of immediate and longer-range drives. Thus, it seems that gaining better drives regulation (or happiness) depends upon improved theory building (or wisdom). Therefore, we will discuss below the limitations posed upon our current ability to build effective theories, and will suggest an approach to expand this ability. However, before approaching theory building in depth, it seems of value to discuss in somewhat greater detail our drives regulation mechanism and focus upon its limitations, or “bugs”. Indeed, it seems that even prior to improvement of our theory building abilities, if we can identify and overcome “bugs” in our drives regulation, it ought to enable us to be happier.
3.2. Psycho-biological pitfalls perpetuate unhappiness
As was stated above, stimuli can gain and lose driving strength. However, at times stimuli gain too much driving strength – for example, in various types of clinical anxiety. In which case, the ability of patients to explore for effective response to the driving stressor may be compromised. For sure, certain stimuli (e.g. life-threatening stimuli) should evoke sufficiently strong brain activity. However, when other stimuli gain such strength, it might be pathological and may lead to rapid and sub-optimal responses and to compromise in the ability to explore for effective drive regulating responses.
Furthermore, we stated above that stimuli gain driving strength on the basis of association with other drives, and that we also believe that stimuli lose driving strength on the basis of dissociation from other drives. However, there is also another brain mechanism, by which stimuli might lose their driving strength – the mechanism of learned inhibition. Indeed, some responses, which are evoked by drives, might be highly improper, especially in various environmental contexts. In-fact, such responses may have led to poor consequences in the past or, in other words, they may have led to punishment. But, punishment (as any other sensory input) is represented in the brain by its perception. Indeed, a certain stimulus may evoke also the perception of punishment, either because there is a correct association between the stimulus and the punishment, and punishment is actually about to follow the stimulus in the current condition, or because of a past, no longer relevant, association between the stimulus and the punishment. In both cases, perception of punishment would often lead to an avoidance response. Thus, the brain embodies an avoidance mechanism, by which such an avoidance response may also inhibit the effects of a given driving stimulus. Thereby, it may inhibit the activation (and thereby the behavioral response) evoked by a drive, which led to inappropriate behavior and thereby was associated with punishment.
However, just like the anxious response, this mechanism of inhibition could also be over-utilized. Thus, various drives could be over-inhibited and the person may suffer from apathy and reduced responsiveness. Indeed, it seems that such a condition may be found in clinical depression and other psychiatric disorders. Thus, strong inhibition would be appropriate for certain driving stimuli, which are associated with punishment. But, in other cases, strong inhibition might be pathological and may also hinder the ability to explore for effective responses.
Altogether, we described two mechanisms, which may lead to cognitive compromise – over-activation and under-activation (due to over-inhibition), at-least as far as major clinical populations are concerned. However, compromise means limiting the ability of the brain to reach effective drives regulation and thereby also to overcome these conditions of over-activation and of under-activation. Thus, these pitfall conditions perpetuate themselves along with ineffective drive regulation (and unhappiness).
Yet, it was shown that these conditions of dysfunctional over-activation and under-activation are prevalent also in the general population, even if to a lighter degree, when compared to psychiatric populations. For example, it was shown that people with certain personality types tend to respond to stressing drives with over-activation (which manifests as more anxious responses), while people with other personality types tend to respond to stressing drives with inhibition and under-activation. But, more than this, it seems that inappropriate anxious or avoidance responses might be phenomena many of us can relate with, under specific circumstances. Thus, altogether, these two pitfalls, of drive over-activation and under-activation, seem to impair, to varying degrees, the ability to regulate drives effectively for many people. Therefore, overcoming these pitfalls will improve drive regulation (and happiness). We will discuss the practicalities of overcoming over-activation and under-activation in the next section.
3.3. Overcoming the perpetuating psycho-biological pitfalls – TBD
4. The transform of wisdom (theory building) and its implications
4.1. The principles of theorizing and its comprehensive generalization
The wisdom of building and improving theories regarding our environment is a peak cognitive achievement of our human society. In this context, a theory could be described as the identification of a set of association rules, among the imprints of the world reality upon our senses. Thus, the effective identification of such association rules, which permits the prediction of important dynamics in our environment as well as the preferable interference in such dynamics, stands at the core of human wisdom. As was stated above, such an ability will enable us to predict and to regulate the drives, which act upon us in various time ranges. Notably, complex theories about our environment are often the accumulative product of a group effort, and not of a single brain. Furthermore, their development may also be based upon technological aids including, nowadays, modern computerized intelligence.
However, as a product of the human brain (or of a society of brains), it should be possible to describe theory building in terms of a neurocognitive computational process, or as an algorithm. Generally, neurocognitive processing have computational limitations. Indeed, the neurocognitive algorithmic description of theory building is no exception in this regard and like any other “neurocognitive algorithm”, it has computational limitations. Furthermore, even a society of such embodiments, which further utilizes external computational aids, would still have computational limitations.
To start with, our ability to identify association rules (or to theorize) is based, as a first step, on our sensation of the environment, which involves the formation of brain representations for the environmental stimuli that act upon us. Furthermore, we mentioned in the transform principles that association between representations is based on co-occurrence of their activation. However, the evaluation of co-occurrence of representation activations is based on some “indexing” of the activations, for example, in time or in space. Then, activations, which occur within a certain proximity window (e.g. in time or in space) could be considered as co-occurring and could be associated. Therefore, the first subprocess of theorizing, which will be presented in some detail below, is comprised of sensory activation of stimulus representations and of their indexing.
Upon this initial subprocess of sensation and indexing, the brain associates between the sensory representations on the basis of the co-occurrence of their activations. In-fact, as we discussed in the transform principles, the brain can associate two or more representations. Therefore, we will discuss below, in some detail, a second subprocess of associating between sensory representations, based on their co-occurrence in a given sample of the environment. We will term this subprocess of association – “bottom-up” association, as it generates the association rules from the elementary sensory representations.
Still, it seems that a major part of our identification of the existence of association rules within a given sample of the environment is based on evaluation of the applicability (and possible adjustment) of previously learned association rules. Often, the current sample might be too small for generating strong new associations (an underfitting error). Furthermore, we hope that associations, which are generated on the basis of a specific sample, might be relevant to other samples, at-least from similar environments, in order to enable prediction and to enable favorable intervention. However, in a given (and especially in a small) sample, there is also a risk for specific (non-generalizable) co-occurrences, which take place either by chance or due to specific circumstances during the sample (an overfitting error). Lastly, thorough sample-based bottom-up association is demanding computationally. Often, it is less consuming to explore top-down the applicability of previously learned association rules.
Therefore, we will discuss below, in some detail, also a third subprocess of evaluating the applicability of previously learned association rules for the current sample. We will term this process of association by checking applicability of previously learned association rules – “top-down” association, as it starts from the rules and looks for their manifestations in the currently sampled elementary sensory representations. Notably, the previously learned association rules are simply the result of previous samples or their combination. So, in a sense, “top-down” association is an exploration for association rules, which are shared by multiple samples. Importantly, “bottom-up” association and “top-down” association may be combined. For example, after partial “bottom-up” processing, the applicability of “top-down” association rules might become more evident. Furthermore, we will also discuss below the impact of the association subprocesses on the first subprocess of sensation and indexing.
To summarize, we suggest to view the theorizing process as being comprised of three subprocesses: (1) sensation and indexing, (2) bottom-up association and (3) top-down association and derived reshaping of sensation. Below we will discuss each of these subprocesses in some detail, as well as the interaction among the subprocesses. For each subprocess we will suggest identifiable components, which together characterize the “algorithm” by which our brains identify the association rules. As was stated above, complex theories are often not the product of a single brain, but rather of a society of brains. Furthermore, we use various external aids, e.g. paper and pencil as well as advanced artificial intelligence, in the process of identifying the association rules. Therefore, our algorithmic characterization will encompass also these aspects of theorizing. Finally, for each of the algorithmic components (except for the basic sensory level, which we take as a limiting given, upon which our theories are formed) we will suggest the possible principles of its comprehensive computational expansion. Thereafter, we will be able to harness these principles, in later chapters, for the suggestion of the practical expansion of our ability to form theories (or, in other terms, of our ability to predict and interfere effectively with our environment, so as to support better drive regulation, or, as we defined it above, to achieve greater happiness).
4.1.1. The sensation and indexing subprocess - dataset specification
Suggested algorithmic components (detailed below):
- The basic sensory layer and its dimensions
- The array of the compound entities of association
- The values set per entity
- Indexing entities
4.1.1.1. The basic sensory layer and its dimensions
We sample the world through our senses and the first layer of the senses is comprised of receptor cells, which are specialized in sensing specific physical attributes – e.g. visual receptors may respond to a specific range of wavelengths in the visible light, thermoreceptors in the skin may respond to a specific range of temperatures, etc. Thus, each specific set of receptors is tuned to sample a specific subset of physical attributes. Physiologically, the span of our sensory entities is diverse, yet limited in both range and resolution. There are light waves we cannot see, sound frequencies we cannot hear, etc.; there are also light waves and sound frequencies within our sensory range, among which we cannot differentiate. Importantly, the limitation in resolution implies that the range of values we can perceive, in a given basic sensory set of receptors, is discrete. Indeed, as each specific set of receptors, which sense specific physical attributes, is comprised of a limited number of sensory neurons, which are often active in a binary mode (all-or-none action potentials), it is reasonable to expect that the sensation of each such physical attribute would involve a limited set of discrete values, or a limited set of discrete intensities of activation.
The activation of the each sensory set, by a transient stimulus, is limited in time and is often manifest by a burst of activity (e.g. action potentials), which lasts less than a second. Thus, each activation of a sensory set has also a temporal value. Furthermore, the receptors are often sensitive to the spatial location of the stimulus (e.g. its place in the visual field or the somatosensory location on the body surface). Therefore, it is possible to view each representation, which is evoked at our basic level of sensation as comprised of four dimensions which are: the physical attribute, its intensity of activation, the time of the activation and the spatial position of the activation.
Allegedly, the limited range and resolution of our sensory abilities has been expanded technologically by various sensory devices, which involve receptors capable of sampling physical attributes beyond our sensory abilities. Seemingly, these devices then transform the expanded physical attributes to information, which is within the range and resolution of our sensation. However, it is clear that at-least certain sensory devices sample values, which are not a simple extension of our senses. Instead, they are derivatives of previous theories, which combine our basic sensations into theoretical constructs, which we then measure (and tend to treat as independent and “real” sensations) – e.g. velocity and acceleration are compounds of spatial position and time. Indeed, one of the greatest challenges of theorizing relates to the validity of forming such effective theoretical constructs.
Furthermore, even devices, which allegedly just expand the range and resolution of our basic sensory abilities, result from previous theories that form associations between external sensors and our basic sensory representations (e.g. transform the output of infra-red sensors to our visible range of vision on the basis of a theory, which relates the activity in these external sensors and our visual system). Thus, both types of extension of our sensory abilities (simple range extension and addition of new constructs of physical attributes) seem to result from theories, which our human cognition generated from other analyses of previous samples of our environment.
In-fact, a major outcome of our discussion below would be the presentation of a comprehensive framework for derivation of such theories and their derived tools for enhanced sensation, as part of the process of theorizing. However, in accordance with the empiricist line of thought, even the most comprehensive theory is limited in its ability to model reality by our basic sensory abilities. The theories we can generate are not of reality but of its eventual sampling through our bodily sensory channels. Thus, according to the above, advanced sensing devices do not really enable any objective enhancement of our basic sensory abilities. They are not equivalent to our basic sensing. Instead they represent (hopefully) effective theories and provide effective compound representations, which are built upon our basic sensing. The use of these compound representations may then enable even more effective association (or better theorizing). Thus, all theories building is based upon our set of limited basic sensory representations on its four dimensions – physical attributes, their intensity of activation, the time of their activation and the spatial position of their activation.
4.1.1.2. The array of the compound entities of association
In the brain
As was also presented in the first principle of the transform, the various sensory modules are arranged hierarchically. Despite some top-down modulation, the organization of the sensory nervous system, beyond its basic level, could be viewed as hierarchical, whereby each tier is comprised of modules, which combine information from specific modules, at their underlying tiers. For example, in the visual channel, the hierarchical organization involves at the elementary tier basic sensory modules, which sense specific ranges of wavelengths (the visual physical attributes), then in the following retinal tiers there is processing of color contrast – by differentiating information from two different types of wavelength receptor cells, brightness – by combining information from various receptor cells, transience of the stimulus – by differentiating information over a time unit, etc. This hierarchical combination continues all the way to the visual cortex, which is comprised of modules with several levels of hierarchy that combine information about line shapes, angles, color, movement, etc. Thus, the various tiers form a hierarchical set of sensory modules, which process physical attributes of varying complexity. Indeed, this organization of a hierarchy of specific sensory modules also applies to the other (non-visual) sensory channels. Furthermore, while more basic modules relate to a specific sensory channel (unimodal), the highest modules combine representations from multiple sensory channels (heteromodal).
However, all together, the number and complexity of modules, in our sensory hierarchy, is rather limited. Figure 1a presents this structure schematically. Importantly, such a well structured hierarchy, promotes certain types of preferred associations – e.g. faster perception of words from combining specific auditory patterns. However, on the other hand, it poses limitations and reduces priority of other possible, less hierarchical, associations – e.g. between representations in different sensory modalities. Certainly, we can identify also associations between values of modules, which are not related by hierarchy. However, such hierarchy crossing association requires the recruitment of memory processes, such as working memory, which are much more limited in capacity.
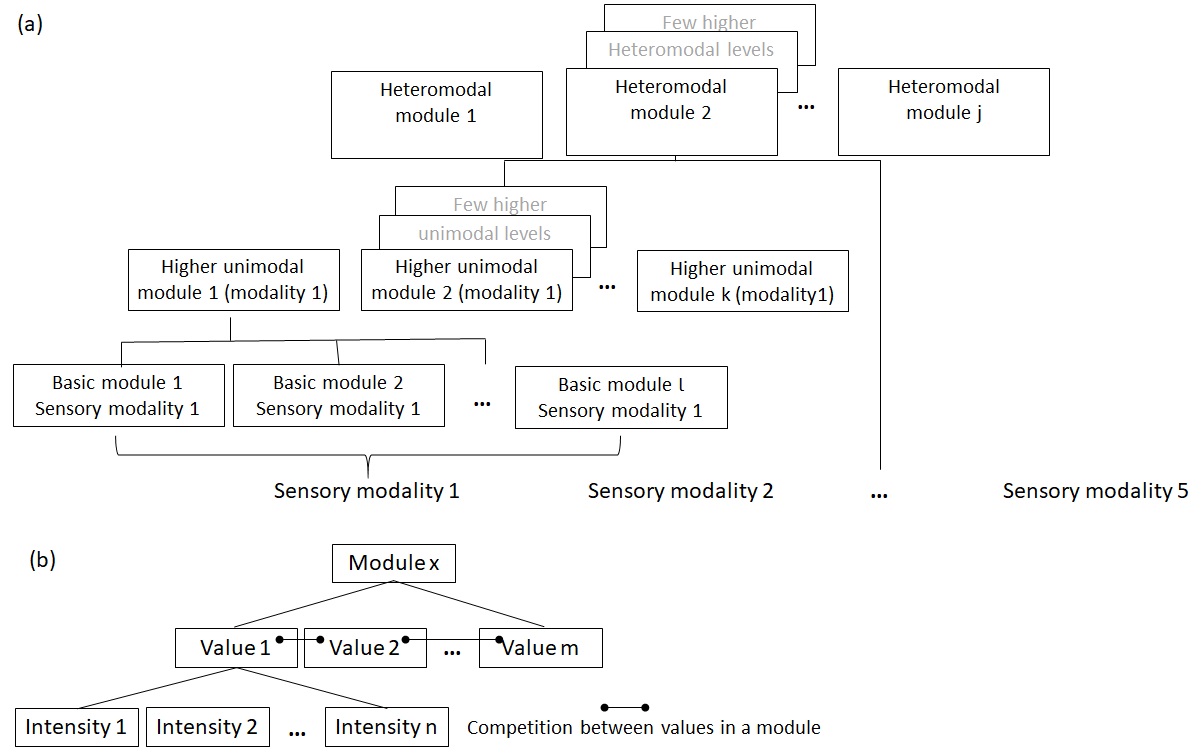
Figure 1: The structure of representation of sensations in the brain
(a) Stimuli are perceived via the various sensory modalities. In each modality, a stimulus activates basic modules of representation. These basic representations could be combined hierarchically to activate more complex representations, which could be unimodal (belong to one sensory modality) or heteromodal (combining representations in various sensory modalities). The depth of the hierarchy, both unimodal and heteromodal, is rather limited. Also, the number of different modules in the brain is limited.
(b) Any module (basic, higher unimodal or higher heteromodal) is comprised of values, which compete among themselves by a mechanism of lateral inhibition. Each of these values (e.g. different faces in the “faces module” or different line tilts in a more basic “lines module”) is activated at any given time with a certain level of intensity out of a discrete set of intensity levels.
Moreover, as was also presented in the first principle of the transform, each module in the hierarchy is a collection of neuronal networks, which may represent alternative, but related, sensory objects. For example, alternative faces are represented in the “faces module” and alternative line tilts are represented in a more basic “lines module”. These neighboring networks, with alternative value representations, compete among themselves through a principle termed lateral inhibition. According to this principle, each active representation inhibits (reduces the activation) of other representations of alternative sensations within the same module. Thereby, rendering a sharper selection of the specific stimulus representation (the “winners take all” principle). Thus, the representation of sensory stimuli is organized in modules, which are comprised of alternative values (neuronal networks).
As was presented in the first transform principle of representation, the neuronal network, which represents a specific stimulus, generates a “burst” response during its temporary sensation. In this burst response multiple neurons “fire” in synchrony. This burst could be graded and sum up to various degrees of network activity and with some variability in duration (usually under the 1-second time-scale). Thus, if a stimulus is sensed more intensely, a stronger response could be evoked in the relevant network. However, the network output activity (the activity, which is sensed by other network units and can be used for association) is a summation of the activity in a limited number of the network’s output neurons. Furthermore, the single neuron activation is binary (on-off, all-or-none). Therefore, taking together the limited number of output neurons per network and the binary activation of each such neuron, there is a limited set of discrete possible intensities of output activation of the neuronal network. Thus, it is possible to consider the representation of each such neuronal network as comprised from a range of discrete (even if at times possibly multiple) intensities (figure 1b).
Thus, similar to the basic representation level, also at higher levels, the brain represents stimuli features (values) and their intensity. Furthermore, as was stated above, also at the higher levels of representation, the activation of the each representation, by a transient stimulus, is limited in time and is often manifest by a burst of activity (action potentials), which lasts less than a second. Thus, each activation of a sensory set has also a temporal dimension (its timing). Furthermore, the hierarchical summation, by which values at a given level are based upon values of lower levels, tend to be spatially oriented, namely to associate values from proximal locations. Therefore, at-least many of the value representations in the sensory hierarchy also have a spatial dimension (position). Thus, altogether similarly to the representation at the basic level, it is possible to view each representation in the sensory hierarchy as comprised of four dimensions which are: a specific stimulus value (specific face, specific line, specific word, etc.), its intensity of activation, the time of the activation and the spatial position of the activation.
Current expansion
It seems that the hierarchical organization of representations in the brain could pose significant limitations on the association process. However, we can easily transform the hierarchical representation of the brain into a table format, and, in-fact, can cancel the hierarchy altogether – figure 2.
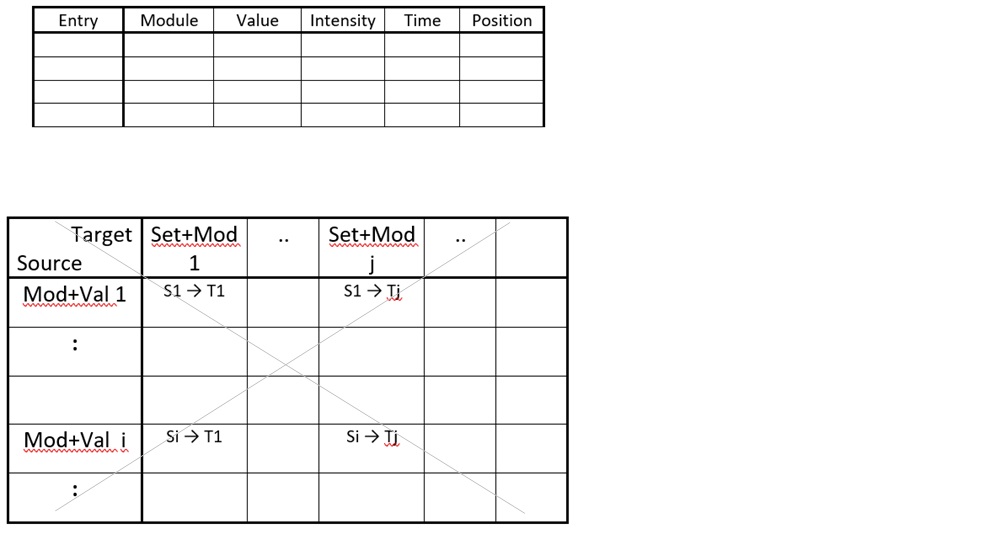
Figure 2: Replacement of the brain’s hierarchical representation of sensation by a general table description
The top table has one entry for each activation of sensory representation, which has, as described in the text, the dimensions of value, intensity, time and position. The hierarchical relation between brain modules could be described by relations between modules and values, as presented in the lower inset. However, as shown in the figure, this hierarchy could be cancelled entirely and not referred to in the table-based association process. In this way, any representation can associate with any other representation, without hierarchical constraints.
In the table format, the discrete combinations of values and intensities, which were described in the brain representation, could be replaced by combined new values. Thus, there is no a-priori need to select only one intensity activation for a given brain value. Furthermore, the entire hierarchical structure could be cancelled and, thus, all associations between entities and values would be feasible, without hierarchical limitation. For the sake of further abstraction away from the strict brain structuring, we would also replace the term brain module with the more abstract term – entity. Thus, we talk about values of entities instead of intensities of values of brain modules.
However, one likely advantage of the hierarchical brain representation is that a higher order value could be activated, even when only some of its underlying basic values were sensed as active. Provided that this partial activation of basic values crosses a combined threshold for activating the representation of the higher value. For example, we need not see, in full detail, both eyes, nose, mouth, etc. in order for a specific face representation to be activated. Yet, this enables flexibility for the sensation in “real-life” environments, in which there are multiple alternative combinations of basic set values, which may activate a higher module value. Furthermore, association is based on co-activation of values, and in a given (finite) sample, there might be a repetition of the high level value, but alternative manifestations of lower level combinations, whereby specific combinations will not occur repetitively enough so as to participate in co-occurrence-based associations. In this regard, the hierarchical structure offers a computational advantage, which could promote effective association in real samples. Interestingly, the values of higher modules were themselves formed on the basis of association by co-occurrence of the basic module values in previous samples.
Thus, in the tabular non-hierarchical organization, there would still be use for compound entities (the general term we use instead of brain modules), which are comprised of various partial combinations of more basic entities, for the very same reason of enabling tolerance in representation for the sake of an effective co-occurrence-based association. Similar to the higher hierarchical modules in the brain, the compound entities are the result of association (also in previous samples, as will be discussed below for the bottom-up and the top-down associations). However, the compound entities would not necessarily form a hierarchical structure, but rather a, more flexible, heterarchical structure. Indeed, such a heterarchical structure might capacitate many more entities in comparison with a strictly hierarchical structure, and external computational expansion enables this increased capacity.
4.1.1.3. The values set per entity
In the brain
We may think we are capable of representing entities with an immense number of values, like the words in a language, or even an infinite number of values, such as the natural numbers. Yet, our representation of entities with infinite values (e.g. the natural numbers), or of entities with an immense number of values (e.g. the words in a language), is comprised from sequences of elementary entities. For example, natural numbers are comprised from sequences of digits, each with ten possible values, and words in a language are comprised from sequences of letters. The number of values in a brain set (entity) is limited and the associations we generate between these values, in different entities or sets, are based on a sequence of associations between the elementary values, which underlie them. For example, the arithmetical operations, which associate between two numbers and their sum, multiplication, or any other mathematical output, are merely a sequence of associations between the elementary digits of these two numbers and the elementary digits of the output.
Current expansion
When we discussed above the array of compound entities, we emphasized the merits of the increased capacity, which is made possible by technological expansion, which promotes non-hierarchical and free formation of compound entities from the basic sensory representations. Allegedly, it might have been useful to expand similarly the capacity of values representation per entity, and indeed this seems to be done by some computational tools. However, in effect, such computational tools involve specific operations (e.g. mathematical operations, lexical operations, etc.), which as we stated above, are based on sequences of operations on the elementary entities (digits, letters, etc.), which underlie the multi-value entities.
Indeed, when we look for associations, which depend on a sufficient count of co-occurrences, as we do with our brain-based intelligence, we need sufficient counts of occurrence of the to-be-associated-values. The capacity increase, which is enabled by computation, could also increase the number of possible entity values. However, if there are too many values for a given sample size, the count of single value activations (and, therefore, the count of co-occurrences in which these value activations take part) might be too small for forming associations.
Comprehensive expansion
Therefore, we do not necessarily seek to increase the number of possible entity values we use and the optimal number of values depends on the sample size. Instead, it seems that a comprehensive expansion of the specification of number of values per entity would better be based upon the division of this entity to elementary entities, such as digits for numerical values and letters for words. The precise determination of the number of elementary entities (and the number of their possible values), which should be used to span a given entity, could be dynamic. It could be determined on the basis of associations found in the current and other samples. The associations formed between the elementary entities could then be combined to form more complex associations, as will be described below for the bottom-up and top-down associations.
4.1.1.4. Indexing entities
In the brain
As was suggested above, the burst activation of each value in any module usually lasts well below a second. However, as was presented in the second transform principle of activity dependent change, association is based on co-activation. Thus, it is possible to derive a temporal “index” of activation, which defines how proximal in time should the activation of two or more values occur in order for them to associate. Certainly, the brain has the ability to reverberate the activation of various sensory representations, e.g. over multiple seconds with the mechanism of working memory. However, the capacity for co-activation of multiple representations, by the working memory mechanism, is rather limited.
Furthermore, the brain representation is also tuned for spatial indexing. Thus, various modules of representation, from the basic (receptor) level and upward, are sensitive to space (e.g. position in the visual field, or somatosensory positioning over the body). With the advancement in the sensory hierarchy, there seems to be gradual blurring of spatial precision. Yet, even in relatively higher levels, representations of spatial proximity tend to associate more than representations from distant loci. Thus, it is possible to state that brain representations are indexed for association in time and in space, with some degree of temporal and spatial tolerance.
The brain also has a limited ability to use various modules, which are unrelated to its innate resolution of time and space, as an index for association. For example, we can explore for associations between characteristics of people (or of any other group of objects). The grouping characteristics (people) is, in this case, the index and the associated characteristics are the representations, which are being associated, such as height and weight, etc. Both the grouping characteristics and the associated characteristics are represented in the brain by values of specific modules, or their combinations, to begin with. However, usually these indexing modules would be of higher levels in the sensory hierarchy. Still, the value modules in the sensory hierarchy, which are beyond the basic level, are built by association between basic level values on the basis of their temporal and spatial proximity (or, in other words, based on their similar temporal and/or spatial indexing). Thus, the mere representation of values, beyond the basic level, is already based on temporal and spatial indices. Therefore, altogether, even such allegedly non-temporal and non-spatial indexing, by the brain, is based upon indexing modules, which are based upon temporal and/or spatial indexing. Thereby, temporal and/or spatial indexing underlies it and underlies any kind of brain-based association.
Current expansion
Technology enables indexing any entity or any combination of entities in the general tabular structure of the sensory dataset, which was described above. Similarly to the use of compound entities described above, the use of multiple entity-based indexing can assist associating in real (finite) samples. Figure 3 demonstrates the potential value of indexing by a specific entity for the identification of association in a finite sample. However, it should be remembered that the entities and values in the tabular dataset are still the result of our brains and thereby, as described above, were formed on the basis of temporal and spatial indexing. Therefore, even this technological expansion of our indexing ability still embeds temporal and spatial indexing.
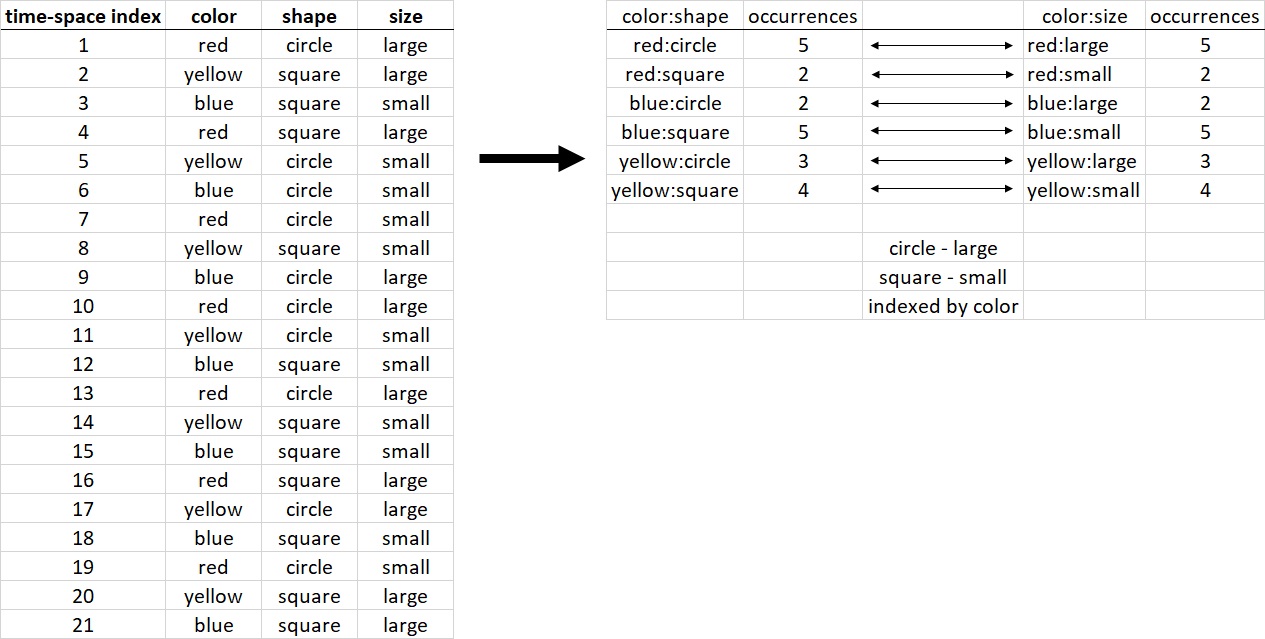
Figure 3: demonstration of indexing by an entity
The table on the left is composed of entries, which could have been derived from a temporal index (e.g. order of “sensation” or input) and three entities: color, shape and size. The association between the entities might be difficult to notice. The table on the right shows the occurrences after re-indexing based on the entity of color. The association between shape and size is now noticeable (and summarized at the bottom).
Comprehensive expansion
But, furthermore, the example in figure 3 of association by color, may also be viewed as a demonstration of a major expansion beyond the basic brain’s ability. As was discussed above, our brains associate on the basis of temporal and spatial indexing. We further noted that higher sensory representation modules (or entities), in the brain, are formed on the basis of this temporal and spatial indexing and, therefore, their use as indexing entities already embeds temporal and spatial indexing. However, we also realized that, at the level of the basic sensory representation, time and space are merely two of the four sensory dimensions, which also include the physical attribute and intensity. At this basic levels, there is no a-priori preference for the representation dimensions of time or space over the representation dimensions of physical attribute or intensity. Each of these dimensions, or their various combinations, could be used equally for indexing. Indeed, figure 3 could be viewed as an example, in which the physical attribute of color (sensed by wavelength receptors at the basic sensory level), was used for indexing instead of the activation timing (or order). Altogether, we can embody a significant external expansion of our association ability by indexing also on the basis of the other dimensions of physical attribute and intensity, and not be limited by the brain’s tendency to index by time and space.
4.1.2. Bottom-up association – Intra-sample association
Suggested algorithmic components (detailed below):
- Indexing association
- Multi-entity bottom-up association
4.1.2.1. Indexing association
In the brain
As was presented above, our sensation of the environment is indexed in time and in space. Furthermore, we suggested that the brain possesses innate, yet limited, abilities for temporal and spatial tolerance, which could be used in the process of association between values. As we discussed, even when higher-level entities are used, by the brain, for indexing, instead of proximal time or space relations, these other entities were probably formed on the basis of proximal time- and space-based associations (of the values of entities at a lower level in the sensory hierarchy). Thus, all together brain-based association is heavily based on proximal time and space indexing.
Current expansion
Using computational expansion, the brain tolerance in indexing could be increased. For example, in methods of spatiotemporal data mining, it is possible to associate between distant (in space and in time) entity values and also to associate between values with large tolerance regarding the precision of their (spatiotemporal) distance. Note that such an extension of distance tolerance may lead to multiple occurrences, of given entity values within the tolerance window. Therefore, the association between values of different entities could be based on the distribution of value counts, within the tolerance window. Still, the expansion of current computational methods involves limiting assumptions regarding distance between the associated values and regarding the tolerance of the association window.
Comprehensive expansion
However, association needs not be limited by ranges of index proximity between the associated entities, or by degree of tolerance regarding their relative distance. It could be possible to associate between activations, which are indexed differently and apart from each other, without any a-priori limitations. For example, values of one entity at given index entries (denoted by i) could be associated with values of another entity at the succeeding index entries (i + 1), or with values of yet another entity at the double entries (i x 2), etc. In order to perceive the feasibility of comprehensive association, between any distant index entries, it is possible to envision the index entries as a special entity and to decompose it to elementary index entities (e.g. the units digit entity, the tens digit entity, the hundreds digit entity, etc.). Then, it would be possible to search for associations between couples of basic entities and basic index entities. Figure 4 demonstrates this approach of coupling elementary entities and elementary index entities as the basis for association.

Figure 4: demonstration of decomposition of data entities and of the index entity to elementary units
The data table on the left is comprised of two entities (E1 and E2) and a running index. E1 values were selected randomly between 10 and 19 with a normal distribution (peaking at 15). E2 values were derived from E1 values with the formula: E2(i) = E1(i-1) x 2, where i is the index entry. Thus, the association of the two entities is between consecutive index entries. The left three columns of the data table show the values of the decomposed unit entities of the index, of E1 and of E2. The right top table presents the coupled occurrence counts of the values of the unit index entity (Iv) and unit E1 (Ev) on the right and of the unit index entity (Iv) and unit E2 (Ev) on the left. The arrows denote the underlying associations of the most frequent combinations. These associations are detailed as value associations and as index associations on the bottom right.
The association between the couples of decomposed index values and basic entities is free of proximity constraints. However, after the association between the decomposed couples, there would be a need to recompose the identification of the index entries, by combining the associations of different index values and the same entity values (e.g. the index units value, the index tens value, the index hundreds value, etc.). Figure 5 captures the feasibility of selecting the best combinations (possibly more than one) of associations between index entries for specific entity values.
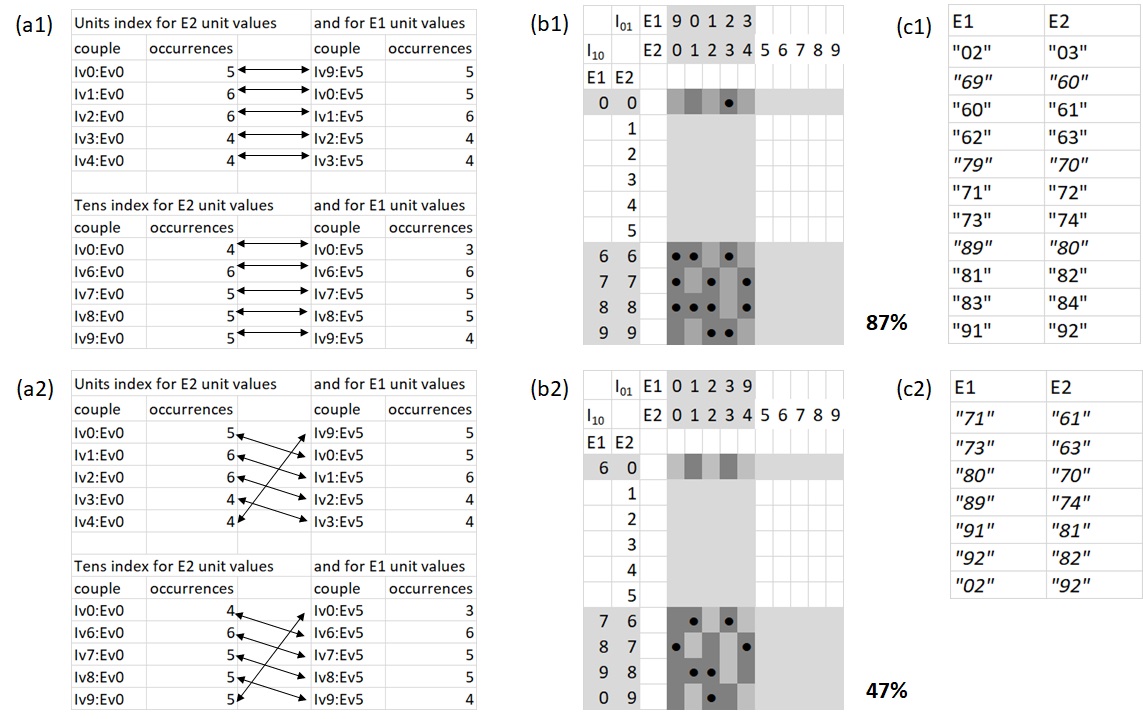
Figure 5: demonstration of the feasibility of recombining the index from its decomposed index entities
(a1) The most occurring couples of the basic index entity and the units value entities E1 and E2, which were presented in figure 4, but only for the units E1 value of “5” and the units E2 value of “0”. The top table is of couples, which are based on the units index values and the bottom table is of couples, which are based on the tens index values. The arrows suggest one possible association between the (index, E1) and the (index, E2) couples.
(a2) Differs from a1 only in the possible association between the couples.
(b1) A graphical depiction of the possible recombination of the tens index values (rows) and of the units index values (columns). The E2 units values from the (index,E2) couples are presented internally and the E1 units values from the (index,E1) couples are presented externally, for both rows and columns. The values of E1 and E2, which were included in the (a1) highest occurring couples are presented and their related lines (for tens index values) and columns (for units index values) are marked in grey. For the sake of demonstration, the grey squares in which E2 value of “0” was found (based on the corresponding tens index value and units index value) are darkened. The black dots show where these “0” values were associated by a “5” value in E1, according to the corresponding tens index value and units index value (which, as was stated above, are the external ones, in both the rows and the columns). There is ~87% coverage of “0”s by “5”s for the possible association between the (index, E1) and (index, E2), which were presented in (a1).
(b2) Similar to b1 only for the possible association, which was presented in (a2). This time the coverage of “0”s by “5”s is only ~47%. Thus, it might be possible to formulate an algorithm, which distinguishes between possible associations and selects the preferred recombination of the index from its decomposed index entities.
(c1) The recomposed indices from the couples association in (a1) and (b1), which were combined of the tens and units index values from the couple with E1 and the couple with E2. The basic relation between the indices was that for a given E2 index entry i, the index entry for E1 is i-1. Three associations, which do not accord with this basic relation are italicized.
(c2) The recomposed indices from the couples association in (a2) and (b2). All associations do not accord with the basic relation, specified in (c1), and therefore they are all italicized.
Thus, altogether, it seems that we can envision a way to expand our ability to associate, while cancelling constraints of index proximity. Each entity value could associate with any other entity value, even if their index entries are distant (as long as there is also association between these index entry values). While there are certainly implementational challenges, the fact that we can envision such comprehensive association between index values at any distance, means that it is within the reach of our extended theorizing ability. Notably, this approach generates associations between pairs of data entity values (in the example of figure 5 value “5” of E1 and value “0” of E2) along with their indexing.
While the origin for our discussion of unlimiting the association proximity constraints was the brain’s indexing by time and space, the above principles of association without limitation on index entries is applicable to indexing by any entity or combination of entities. Altogether, for any combination of sensory dimensions (time, space, physical attribute or intensity), which may underlie the index, we showed above the feasibility of associating pairs of values with any type of relation between their indexing entries (regardless of proximity).
4.1.2.2. Multi-entity bottom-up association
In the brain
We already discussed, in the context of the previous sub-processes, as well as in the context of the second transform principle of activity dependent change, the manner by which association between representations is based upon their co-occurrence. If two representations are co-active in the brain, the connectivity between them strengthens and thereby they become more associated and the opposite occurs when the two representations are active separately from each other. Importantly, the associability of pairs of representations depends upon the physical connectivity between the brain modules to which they belong. Thus, pairs of representations, which belong to modules that are strongly connected, will associate more, while pairs of representations, which belong to modules, that are not so connected, will associate less effectively, given the same degree of co-activation. Nevertheless, memory mechanisms permit association of representations, which belong to less connected modules, by offering indirect connectivity.
Furthermore, we also mentioned, in the context of the second transform principle of activity dependent change, that association can form between groups of representations (more than just two). In-fact, the hierarchical structure of sensory representation embeds association of multiple representations. For example, the representation of face is basically an association of multiple co-occurring face parts. However, the association of groups of representations, which do not belong to strongly connected modules (by way of the hierarchical structure) and may rely more on memory processes, seems to be more limited.
Moreover, we emphasized above also the limitations imposed upon the “bottom-up” association process in terms of index (temporal and spatial) distance and tolerance. Altogether, these limitations also seem graver when considering the association among groups (more than just two) of representations.
Current expansion
Various data mining methods are in computational use to enhance our association abilities, especially when multiple entities and values are involved. However, each data mining method has its underlying assumptions and, thereby, each such method limits the range and the preference of possible associations, which could be discovered and, even with the combination of multiple methods there are associations, which would not be made and multiple others, which would not be preferred. Therefore, the challenge would be to envision a comprehensive approach, which could expose all the possible associations in a sample, without limitation.
Comprehensive expansion
The key for such a theoretical generalization of multiple-entity associations lies again in the finiteness of the set of discrete entity values, which was described above, or in the limited set of discrete values of the elementary entities, which comprise them. For example, let us assume that a standard non-linear data mining reached the following formula, which associates Y, X1 and X2: Y=2X1+X22 and that X1 and X2 are elementary digits and we divide Y to Y01 (units digit) and Y10 (tens digit). In this case if X1=1 and X2=2 then Y01=6 and Y10=0, if X1=1 and X2=3 then Y01=1 and Y10=1, etc. Thus, at the level of the elementary discrete value pairs there would be an association between the X1 values and the Y01 values, between the X1 values and the Y10 values, between the X2 values and the Y01 values and between the X2 values and the Y10 values. However, given a sufficiently large sample, such an approach, of associating the elementary values, would work for any formula of association, which would be arrived at, by any data mining method. Therefore, the approach of associating elementary entity values is a conceptual way to generalize the outputs of any data mining method in a comprehensive manner. Certainly, the use of a specific data mining method may enhance performance and enable the extraction of the formula from a smaller sample. However, our focus here is not in the specific implementation, but instead on the description of what a comprehensive expansion of our theorizing abilities can reach. Thus, according to the above, we can certainly envision a way to generate all possible association formulae between pairs of entity values.
Furthermore, at-least theoretically, it is possible to associate between elementary discrete values by logical AND – in which case, the Y value is y if either the X1 value is x1 and the X2 value is x2. It is also possible to associate such values by logical OR – in which case, the Y value is y if either the X1 value is x1 or the X2 value is x2. Logical OR association is also possible between two X1 values – e.g. the Y value is y if X1 value is either x11 or x12. The associations may involve any number of multiple entities and entity values. However, at the level of the values they will still follow a Boolean logic form and would be describable with AND/OR predicates. The elementary items in these logical expressions would be the values or their negations (x1’ associates with y if at the given index entries, which relate X1 and Y values – see previous sub-process – the lack of occurrence of the x1 value, in the X1 entity, associates with the occurrence of the y value in the Y entity).
However, according to De Morgan laws, it is possible to describe any logical expression in a disjunctive normal form – where the elements are values or their negations and they are combined at the first level by logical ANDs and at the second level by logical ORs. Therefore an algorithm, which aims to find the combinations of source entity values X1, .., Xn that predict a target entity value Y, could search first for pair associations of Xi and Y and Xi’ (negation) and Y, then search for logical ANDs between these pairs, building AND sets of Xi,j,k and their negations and then form logical ORs between the AND sets. Such an algorithm will explore, in principle, all possible combinations of entity associations and thereby all multi-entity formulae.
The sub-processes, presented thus far, seem to suggest a comprehensive theoretical extension to our neurocognitive ability of theorizing. However, they might not be sufficiently effective for analyzing associations in a finite sample as they are based on discretization of the data, which reduces occurrence counts and leads to underfitting of the discovered associations. To begin with, a sample size certainly limits the brain, as well as the various data mining methods, from finding comprehensive associations. Furthermore, the increased discretization, suggested above for the sake of theoretical comprehensiveness of analysis, is certainly likely to reduce the efficacy of associating even further. In a way, the various data mining methods could be viewed as means to overcome such underfitting, at the expense of using specific limiting assumptions regarding the nature of the preferred association rules. Similarly, overfitting would also be a risk in case of small samples.
Therefore, we would like to analyze and to generalize, in principle, also the human sub-process of correcting for underfitting and for overfitting. This is the goal of the next section. Again, the purpose of this chapter is not implementational, but rather to suggest we have the ability to envision a comprehensive process of association and theorizing. After we describe the principles of such a comprehensive process, practical implementations would follow. If we can imagine the expansion of our cognitive ability to generate theories, we will find a way to implement this vision.
4.1.3. Top-down association – Inter-sample association
Suggested algorithmic components (detailed below):
- Top-down association
- Latent factors search
4.1.3.1. Top-down association
In the brain
In practice, we often look for associations in samples of limited size. Therefore, the number of occurrences of various entity values is often too small for association, which is based solely upon co-occurrence. Furthermore, with small samples there is greater risk for underfitting as well as for overfitting. Thus, we often explore for association rules by a process of inductive reasoning. In essence, this process is heavily based on exploration of the adequacy of various pre-defined association rules to the current sample. Notably, these association rules were in-fact learned and established on the basis of previous samples.
This exploration among pre-learned association rules is guided by our prefrontal cortex with “top-down” exploration of the entities in the relevant sensory modules. Generally, the elementary form of the exploration is by inductive reasoning. In essence, this process is based on exploration of the adequacy of various pre-defined association rules with the current sample. Such exploration is content-dependent – e.g. we may explore first among a certain set of mathematical association rules if the sample is numerical and among another set of linguistic association rules if the sample is comprised of words, etc. However, we are also capable for analogical reasoning. Namely, of exploration, in a manner which crosses content boundaries and is based upon similarity of the distribution of entity values and upon similarity in the distribution of relations between entity values in the different samples. Thus, analogical reasoning does not assume a-priori semantic knowledge about the sample.
In fact, in a sense, inductive reasoning could be viewed as a special case of analogical reasoning. This is because each inductive rule could be described in terms of the distribution of entity values and of the distribution of the inter-entity value relations. Thus, we can expect that if a given inductive rule is applicable in a specific sample, we would find similarity in the distribution of entity values and entity relations between the specific sample, and the distribution of the entity values and relations of the inductive rule. Thus, in principle, we can describe any matching with association rules in terms of analogical reasoning, or, in other words, as being based on similarity in distribution of entity values and of value relations. Even though, in practice our brain may utilize heuristically content semantics.
We further possess the ability to explore for association rules by chaining several pre-defined rules in order to identify associations in the current samples. Nevertheless, this ability of the brain to chain functions is limited in capacity. Indeed, this “top-down” association ability of the brain, without and furthermore with chaining, is based on processes of executive function, working memory and sustained attention, which are limited in capacity. Therefore, we often utilize external aids for the effective implementation of exploring for association rules, from pencil and paper (and their historical predecessors) to advanced computing.
Current expansion
An advanced method for improving the human top-down exploration process for association rules is symbolic regression. In its basic form, this method starts with a set of available association rules or, for quantitative data, with a set of formulae. These formulae are applied at any order on the sampled data and effective formulae, or association rules, are maintained. Combinations of successful rules are further generated and this hopefully leads to the selection of effective formulae, or chains of association rules, which identify associations in the sampled data. However, this process of symbolic regression is still led by a human by defining the set of formulae, which may be used as a-priori rules. Therefore, we discuss below its possible comprehensive expansion and automation.
Comprehensive expansion
For a given sample, every association is describable as a bi-graph. The nodes in the source partition are certain entity values, or the values of a set of entities, which are combined by a logical predicate, and the nodes in the target partition are other values of another entity. The edges of each such a bi-graph can represent possible association relations between these source and target entity values. Importantly, from each sample it might be possible to derive multiple association relations between various combinations of entities. Thus, the associations in a given sample could be described by a set of such bi-graphs, among which there are partial overlaps in terms of entities, values and association relations. The theoretical generalization of analogical reasoning would be a comprehensive exploration of similarities between such sets of bi-graphs, which are related to the different samples. Since, as was stated above, the rules, which are evaluated for adequacy in a given sample, stem from associations in other samples. The similarity between sets of bi-graphs would be preferably based only on the distribution of values and of the value relations, without reference to content semantics (or to the labeling of entities and of values). As we discussed above, even content-based inductive reasoning could be viewed as a private case of content-free association. Notably, content free association would enable the breaking of possible barriers, which may prevent identifying of certain relations between samples of allegedly different content.
Importantly, it should be pointed out that at times the relation between the sets of bi-graphs might not be of equality – namely a similar number of values in the relevant entities, or entity combinations, with similar value distributions and similar inter-value relation distributions. Instead, one set might be a subset of the other, or there might be a significant, yet still partial, overlap between the bi-graph partitions. These types of partial relations might indicate underfitting or overfitting in the “bottom-up” associations in the involved samples. Thereby, such underfitting and overfitting could be corrected.
Finally, in resemblance to the brain’s ability to chain rules, similarity could also involve a certain sample and a chain of other samples. For example, the values at the source partition of a given sample X might have similar distribution to the values at the source partition of another sample Y1. However the target values and the relations between partitions might be different. Nevertheless, the values at the target partition of Y1 might have similar distribution to the values in the source partition of sample Y2 and the values of the target partition of Y2 might have similar distribution to the values of the target partition of X – and the X relations might have similar distribution to the chaining of the relations in Y1 and in Y2. Thus, the comprehensive exploration of similarities between sample includes also sample chains.
4.1.3.2. Latent factors search
In the brain
On multiple occasions, the associations for a given sample would be only partial due to the presumed impact of latent entities and values, which were not included in the analysis. In-fact, it seems that the identification of such an impact and the search for latent entities and values is a major sub-process of theory building. Indeed, studies demonstrated our ability to identify the existence of such latent factors from early childhood, and in the history of science, on multiple occasions, the existence of entities and values was derived theoretically first, and only later on supported also by experimental data.
If the latent entities and values are present in the current sample, and were simply missed in the analysis, we can include it in the association relation for improving its precision. This condition could be identified by the “bottom-up” association process, by the “top-down” association process, or by their combination. However, as was described above, the embodiment of these processes by the brain is highly limited in its capacity. Furthermore, in multiple such occasions, it might be that the latent entities are in-fact compound entities, which, as described above, are a combination of multiple elementary entities. However, as we discussed, in the brain there is strong preference for a limited set of compound entities, which are part of the hierarchical set of brain entities. Thus, other heterarchical compound entities, which might form the latent factor, are less likely to be identified as such.
Yet, on other occasions, the latent entities and values are not part of the current sample to begin with. Still, research regarding our exploration for such latent factors suggests we use analogical reasoning to identify similar sample sets. Such exploration may identify similar sets, which may also include entities or values that improve the partial associations of the original sample. In which case, we can try to include in further samples from the same source also these additional entities and values. As described above, the ability of our brain for analogical reasoning is limited. Sometimes, for example, in the context of scientific theories, this analogical reasoning quest for latent factors may be described as involving intuition and insight. However, cognitive analysis of such processes seems to suggest that insight is merely the emergence of the results of unconscious exploration into consciousness. Thus, all in all, we have a limited ability to identify the existence of latent factors and to explore for them in the current sample, or in other samples.
Current expansion
Various methods have been used to analyze latent factors – e.g. hidden Markov models. Each of these methods is based on specific assumptions regarding the latent entities and values and their relation to the sampled entities and values. Furthermore, these methods are based only on the sample without automatization of the analogical reasoning of exploration for finding candidate latent variables in other samples. It seems that this exploration remained thus far human, despite the advances in its cognitive modeling, which were already mentioned above. Therefore, below we discuss principles for its comprehensive computation, without human intervention.
Comprehensive expansion
In-fact, the task of identifying this latent factor, could be divided to three different levels: the current (i) sample itself, (ii) other similar existing samples and (iii) other existing samples in general or, possibly, entity values in futuristic samples, once they will be collected.
When the latent entities and values exist within the current sample, they may have been missed because of underfitting, despite the co-use of bottom-up and top-down association. It would then be possible to explore in a comprehensive manner, among all possible elementary and compound entities and values, for candidates with a distribution of value that can combine with the partial association for its improvement. Note that this is a focused analysis, in comparison with the more general and comprehensive analysis of the basic association sub-processes (bottom-up and top-down).
As was suggested above, the latent factor could also be explored for in other samples, even if its equivalence is not found in the current sample. For example, let us assume we have a partial association in sample X and we now explore for latent entities and values in sample Y. We can denote the source (partition) entity values (ev), which participate in a partial association as XSev and the target (partition) entity values, which participate in a partial association as XTev. Let us assume related entity values in sample Y so that YSev is similar to XSev and YTev is similar to YTev and there is also similarity in the partial association between the pairs in the different samples. There might exist another entity and values in Y – YS2ev, such that the combination of YSev and YS2ev associates more strongly with YTev. Then, it might be advisable to look for an analogue entity (in terms of values distribution) in the environment from which X was sampled, for the sake of future samples / re-samples. Furthermore, as was described for the “top-down” association, similarity could be analyzed, for the purpose of identifying candidate latent factors, also between the partial associations sample, on the one hand, and a chain of other samples, on the other hand.
Note, that given a large enough set of samples and their derived association rules, currently prevailing methods of exploring for latent factors, like hidden Markov models, would emerge from such chaining. This is because they are merely based on a sequence (chain) of arithmetic operations (associations), and as we described above, each such association is based on a small set of relations between elementary entities (or, in the arithmetic case, of digits). However, if the samples set is large enough, such underlying associations are likely to be already included in it. In-fact, the view of the advanced methods, as composed of chains of associations, touches upon the essence of this chapter. Arithmetic formulae, like any other association rule in any domain, are comprised of a limited set of underlying associations and their chaining. Therefore, gradually improving “top-down” association and also exploration for latent factors, on the basis of other samples, is expected to yield effective (and gradually improving) results after the derivation of underlying associations from a limited set of samples.
Finally, it is possible to analyze the distribution of the latent entities and values, as a basis for their analysis in any sample, or even in futuristic samples. For a simple example, if a certain source value SV relates with two target values – TV1 and TV2 – 50% of the occurrences with each, then a binary latent entity with values LV1 and LV2, which co-occur with SV 50% of the time each, can improve the association – SV AND LV1 may co-occur with TV1 100% of the time and SV AND LV2 may co-occur with TV2 100% of the time. Such a latent entity and the current source entity could be combined using logical AND (in other cases other predicates may be used). It would then be possible to explore the various samples of entities, or entity combinations with similar value distributions, in the environment of the target sample, for the sake of future samples / re-samples. It is important to note that this distribution should also involve specification of index relations between these new candidate new entities and the original entities of the target sample.
Summary of the principles for a comprehensive algorithm of theorizing
In the chapter above we divided the process of theorizing to three subprocesses: (1) sensation and indexing, (2) bottom-up association and (3) top-down association and derived reshaping of sensation. For each subprocess we discussed its algorithmic components in the brain and with current technology. Thereafter, we described the possible comprehensive expansions for the various components (except for the first component of the basic sensory layer, which could be considered a given, upon which we can build theories). The combination of all these expansions would generate a comprehensive algorithm for associations, or theorizing. In the next chapters we will discuss the possible implications of such comprehensive algorithmic for our ability to predict and interfere effectively with our environment, so as to support better drive regulation, or, as we defined it above, to achieve greater happiness.
4.2. Analysis of scientific advancement – TBD
4.3. Comprehensive expansion of our ability to form theories – TBD
Recommended scientific reading:
- On the hierarchical representation in the brain:
Mesulam, M. M. (2000). Principles of behavioral and cognitive neurology. Oxford University Press.
- On the representation within each brain module:
Mountcastle, V. B. (1998). Perceptual neuroscience: The cerebral cortex. Harvard University Press.
Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. The Journal of physiology, 160(1), 106-154.
- On the representation of values by a neuronal network:
Shahaf, G., Eytan, D., Gal, A., Kermany, E., Lyakhov, V., Zrenner, C., & Marom, S. (2008). Order-based representation in random networks of cortical neurons. PLoS computational biology, 4(11), e1000228.
- On the association by co-activation:
Hebb, D. O. (2005 edition). The organization of behavior: A neuropsychological theory. Psychology Press.
Bliss, T. V., & Lømo, T. (1973). Long‐lasting potentiation of synaptic transmission in the dentate area of the anaesthetized rabbit following stimulation of the perforant path. The Journal of physiology, 232(2), 331-356.
- On drive regulation:
Hull, C. L. (1943). Principles of behavior: An introduction to behavior theory.
Shahaf, G., & Marom, S. (2001). Learning in networks of cortical neurons. Journal of Neuroscience, 21(22), 8782-8788.
- On dysfunctional drive regulation:
Shahaf, G. (2016). a possible Common neurophysiologic Basis for Mdd, Bipolar disorder, and schizophrenia: Lessons from electrophysiology. Frontiers in psychiatry, 7, 94.
- On the representation of infinite entities:
Lakoff, G., & Núñez, R. E. (2000). Where mathematics comes from: How the embodied mind brings mathematics into being. AMC, 10, 12.
- On latent entities:
Bridgman, P. W., (1927). The logic of modern physics (Vol. 3). New York: Macmillan.